

The NVIDIA Jetson Xavier NX is a development kit that supports the deployment of Cloud Native Applications. In case you are wondering what Cloud Native Applications are all about, you can visit our introductory guide – “NVIDIA Jetson Xavier NX – Cloud Native Computing : What does it mean?“. It should give you a certain understanding to the topic.
As we understand, being Cloud Native is all about containerization. As the hardware and infrastructure is abstract, there is a need to create a specialized layer within the container operating software to allow communication to specialized hardware. In the instance of the NVIDIA Jetson Xavier NX, it comprises of a dedicated Volta based GPU for accelerated AI compute. As expected, since it is considered a specialized hardware, a container which uses virtualized hardware, will not have access to the GPU. This is where the NVIDIA Container Runtime comes about.
NVIDIA Container Runtime
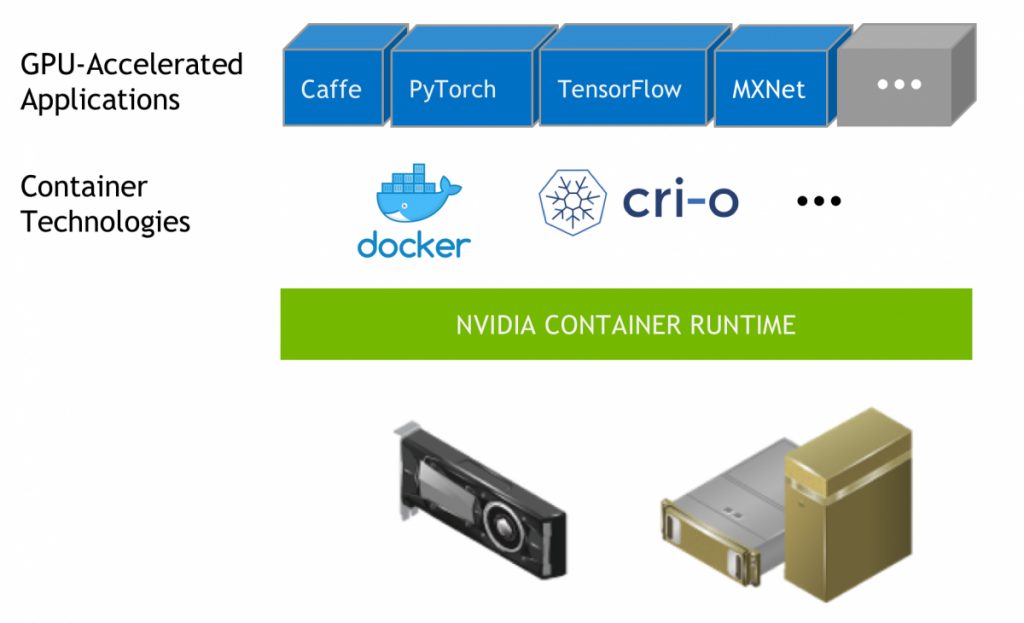
NVIDIA has used Docker as their core technology of choice to going Cloud Native. They have built the NVIDIA Container Runtime, which runs as an add-on to the main Docker Engine in order for containers to have direct access to the GPU. This way, all GPUs are also virtualized for the containers, which can then take advantage of the GPU’s strengths in AI compute(or other applications).
The NVIDIA Container Runtime is not just made for the Jetson series of products. In fact, any system from small development kits, to personal computers, workstations, server class systems and even high performance computers, can make use of the same runtime to have access to NVIDIA GPUs. To learn more about the installation of NVIDIA Container Runtime to Docker, you can follow the instructions from the NVIDIA Container Runtime GitHub repository.
NVIDIA Cloud Native Demo
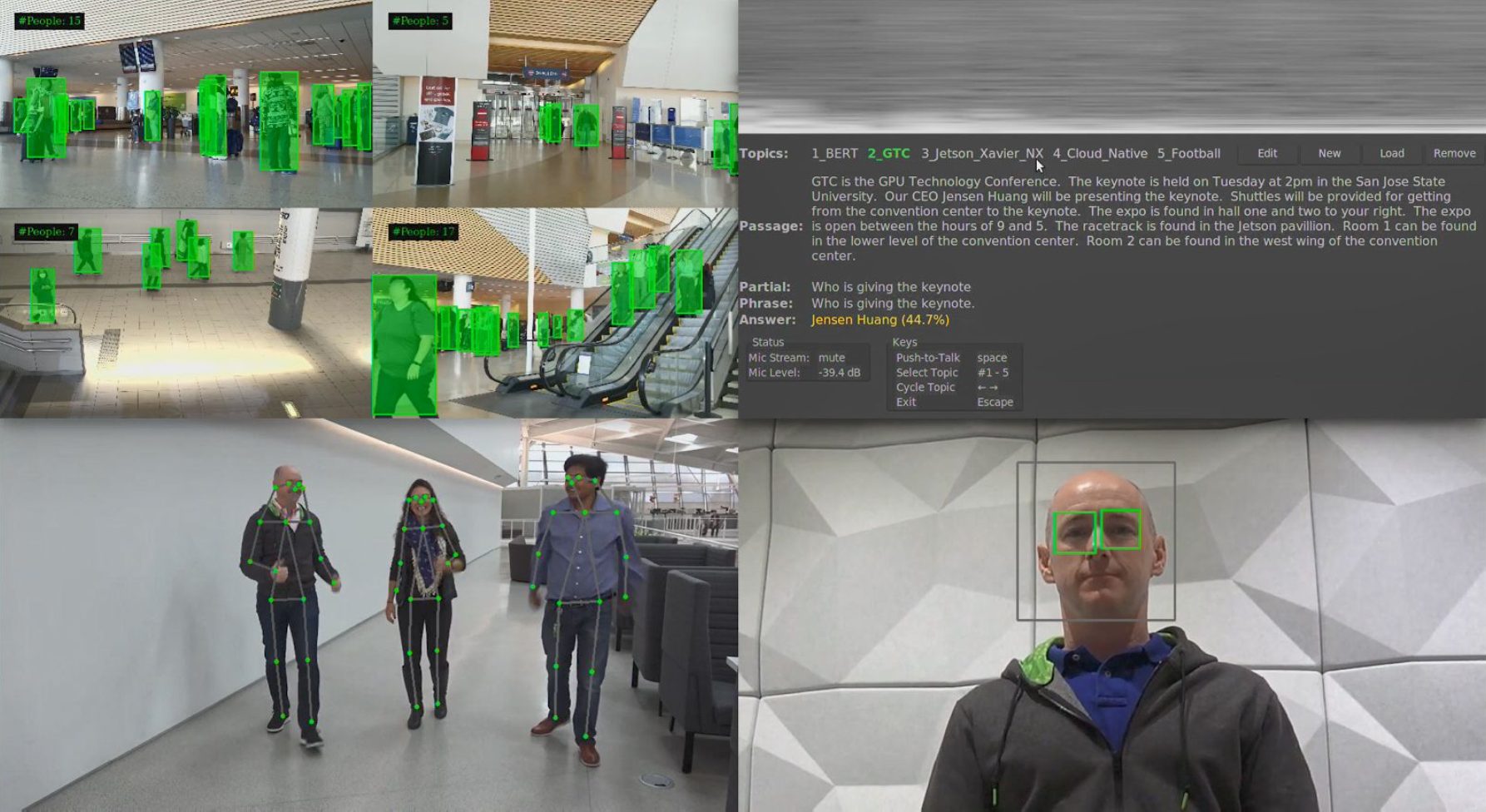
To have a feel of how easy it is to deploy Cloud Native Applications, we made use of the demos which NVIDIA provided. In this demo, we are also going to show the capabilities of the Jetson Xavier NX, which is capable of running multiple networks concurrently and to deliver real-time performance. It simulates the types of AI applications that are required to run a service robot. This service robot is expected to complete these tasks:
- Identify humans
- Detect when a customer is talking to it
- Understand where a customer is pointing to while interacting with it
- Understanding what a customer is asking
- Provide useful answers
As such, the NVIDIA demo uses the following AI models to achieve this
- People Identification to identify humans
- Gaze detection to detect when a customer is talking to it, as opposed to talking to someone else
- Pose detection to detect customer’s pose
- Speech recognition detect words in sentences spoken by the customer
- Natural language processing to understand the sentence, including context, to provide relevant answer back to the customer
Setting up and deploying the Demo

We will take 4 containers from the NVIDIA private repository to achieve all the above feature
- DeepStream Container with people detection
- A Resnet-18 model with input image size of 960 x 544 x 3. This model was converted from TensorFlow to TensorRT
- Pose container with pose detection
- Resnet-18 model with input image resolution of 224 x 224. The model was converted from PyTorch to Tensor RT
- Gaze Container
- MTCNN model for face detection with input image resolution of 260X135. The model was converted from Caffe to TensorRT
- NVIDIA Facial landmarks model with input resolution of 80X80 per face. The model was converted from TensorFlow to TensorRT
- NVIDIA Gaze model with input resolution of 224X224 per left eye, right eye and whole face. The model was converted from TensorFlow to TensorRT
- Voice Container with speech recognition and Natural Language Processing
- Quartznet-15X5 model for speech recognition which was converted from PyTorch to TensorRT.
- BERT Base model for language model for NLP which was converted from TensorFlow to TensorRT.
As NVIDIA has already prepared all the images for deployment, all we needed to do was to pull the images from the NGC Container Registry. Just 4 commands, each for 1 container, and we were good to go. They have also provided a startup script, which starts every container and arranges their window nicely on the monitor.
See the demo in action below:
Final Words and Comments
It’s amazing how being Cloud Native has simplified software development and deployment. With the readily available trained models that are on the cloud, we can quickly and seamlessly deploy and configure AI applications without much effort.
The NVIDIA Jetson Xavier NX has also shown us the potential that it brings to the market. In the past, due to hardware limitations, it’s quite impossible to deploy multiple AI applications onto a edge device at an affordable manner. Now, the NVIDIA Jetson Xavier NX, which is equipped with the higher performance and efficient Volta GPU architecture, is able to bring a new paradigm to AI edge computing and inference.
We look forward to many amazing new applications that can be enabled by the NVIDIA Jetson Xavier NX development kit.



