

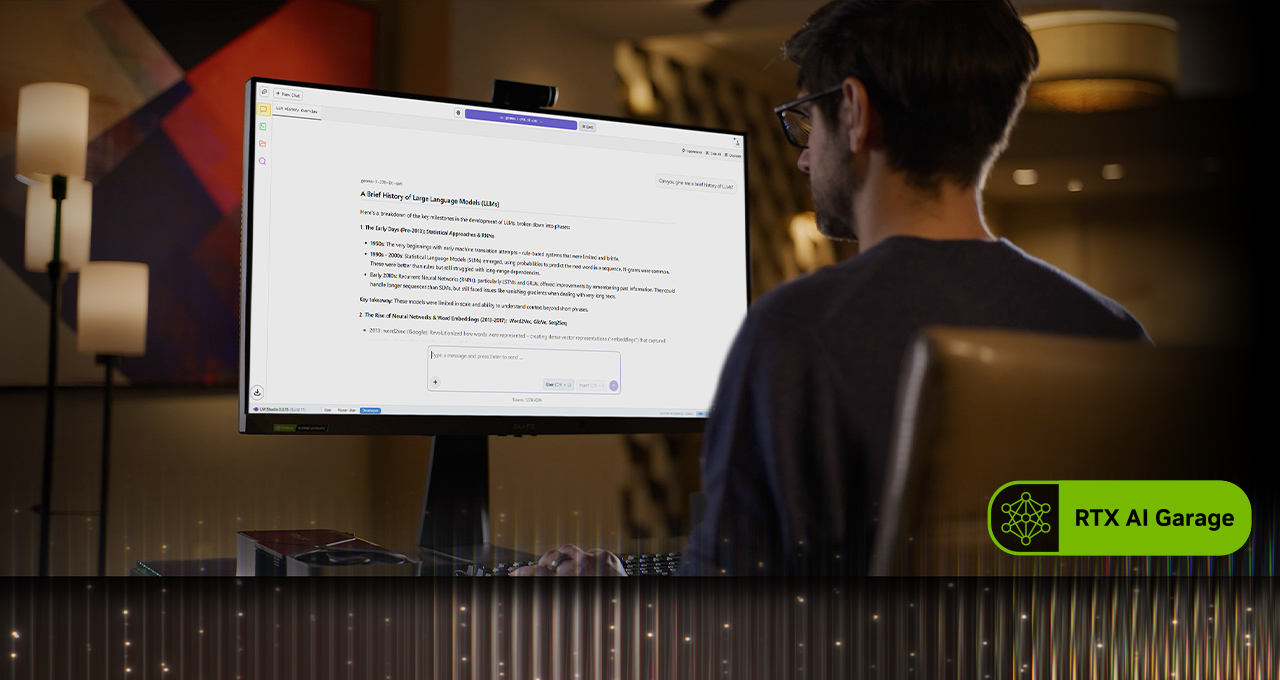
Running large language models locally has long appealed to users seeking privacy, control and freedom from subscription limits, but quality often lagged behind cloud-based options. That gap is narrowing as open-weight models like OpenAI’s gpt-oss and Alibaba’s Qwen 3 become more widely available, offering higher output quality directly on PCs. NVIDIA is positioning RTX hardware at the center of this shift, optimizing applications and frameworks that bring local AI to life.
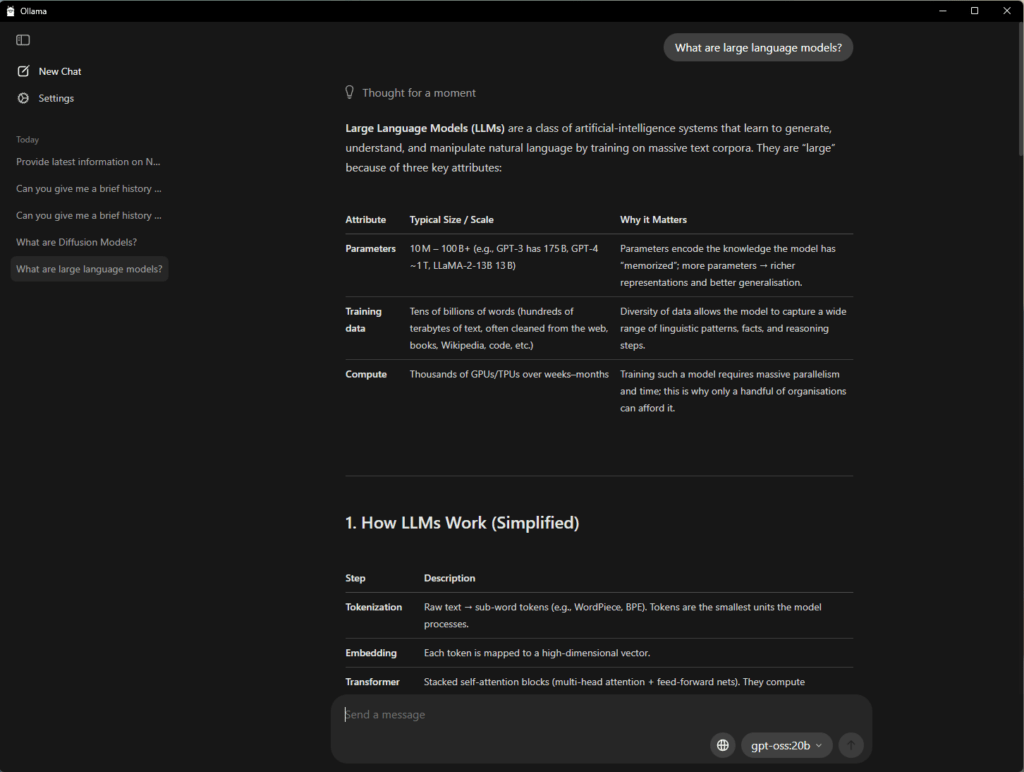 Ollama has emerged as one of the easiest entry points for users exploring LLMs on PCs. The open-source app supports drag-and-drop PDF prompts, conversational chat and multimodal workflows, while NVIDIA’s collaboration has led to faster performance on models such as gpt-oss-20B and Google’s Gemma 3, better memory utilization, and improved stability across multiple GPUs.
Ollama has emerged as one of the easiest entry points for users exploring LLMs on PCs. The open-source app supports drag-and-drop PDF prompts, conversational chat and multimodal workflows, while NVIDIA’s collaboration has led to faster performance on models such as gpt-oss-20B and Google’s Gemma 3, better memory utilization, and improved stability across multiple GPUs.
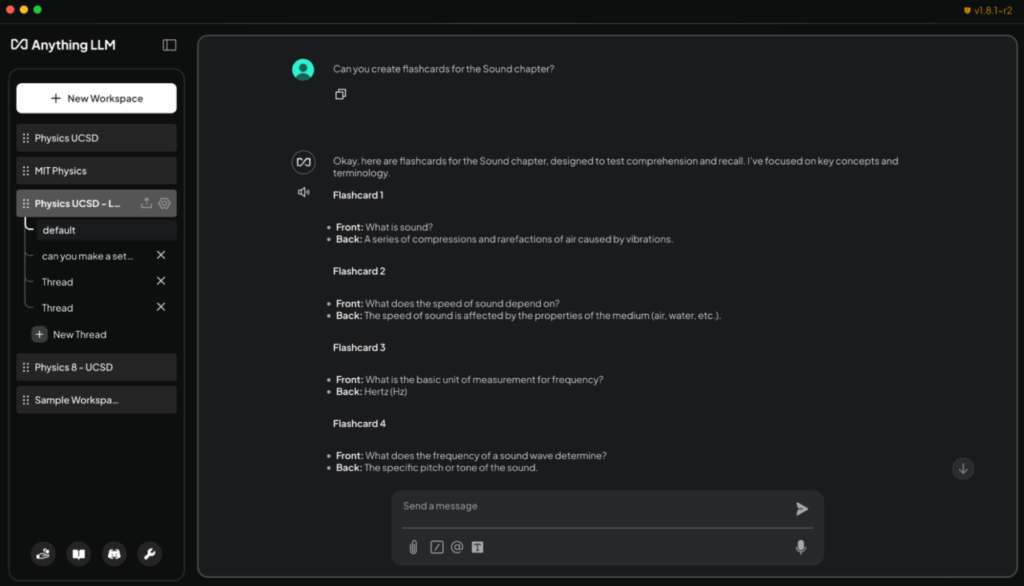 Developers can extend Ollama further with open-source projects like AnythingLLM, which enables the creation of custom AI assistants drawing on personal knowledge bases.
Developers can extend Ollama further with open-source projects like AnythingLLM, which enables the creation of custom AI assistants drawing on personal knowledge bases.
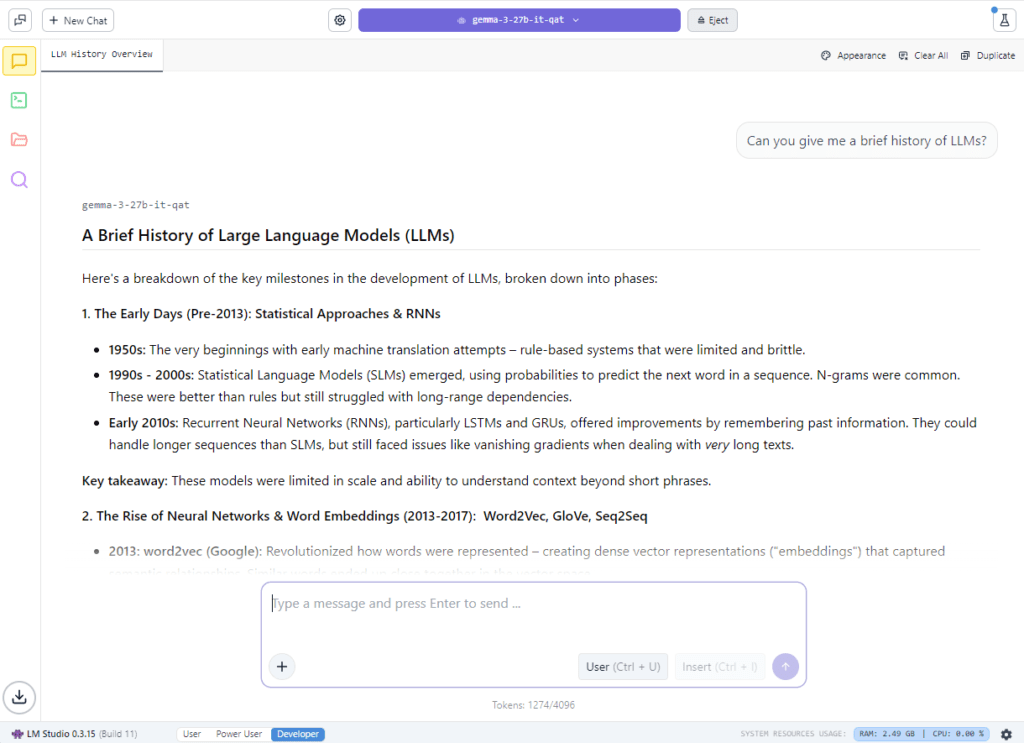 LM Studio, powered by the llama.cpp framework, is another tool that benefits from NVIDIA’s ongoing optimization efforts. The latest updates include support for Nemotron Nano v2 9B, a hybrid-mamba model, along with default Flash Attention for up to 20 percent faster performance and kernel-level improvements for popular workloads.
LM Studio, powered by the llama.cpp framework, is another tool that benefits from NVIDIA’s ongoing optimization efforts. The latest updates include support for Nemotron Nano v2 9B, a hybrid-mamba model, along with default Flash Attention for up to 20 percent faster performance and kernel-level improvements for popular workloads.
For developers and hobbyists, LM Studio offers a simple way to run different models locally, interact in real time, or serve endpoints for integration into broader projects.
 NVIDIA is also extending AI beyond productivity. Project G-Assist, an experimental assistant for gaming PCs, now adds laptop-oriented controls in its latest update. New features include app profiles for performance and efficiency management, BatteryBoost adjustments for smoother gameplay on battery, and WhisperMode controls to cut fan noise by half. With its plug-in framework, G-Assist can be customized and expanded by the community.
NVIDIA is also extending AI beyond productivity. Project G-Assist, an experimental assistant for gaming PCs, now adds laptop-oriented controls in its latest update. New features include app profiles for performance and efficiency management, BatteryBoost adjustments for smoother gameplay on battery, and WhisperMode controls to cut fan noise by half. With its plug-in framework, G-Assist can be customized and expanded by the community.
Together, these initiatives reflect NVIDIA’s strategy to embed local AI into everyday PC use cases. Whether through study companions powered by AnythingLLM, model experimentation in LM Studio, or voice-controlled system tuning with G-Assist, RTX PCs are increasingly serving as the foundation for fast, private, and flexible generative AI.



