

NVIDIA has introduced the latest TensorRT-LLM software, which has successfully doubled the output of its high-end H100 cards through optimization efforts.
This achievement is the outcome of close collaboration with leading companies, such as Meta, Anyscale, Cohere, Deci, Grammarly, Mistral AI, and MosaicML all of whom heavily rely on AI in their daily operations.
Their common goal is to accelerate LLM inferencing through advanced software techniques and there you have it, NVIDIA TensorRT-LLM.
Compatible with Ampere, Lovelace, and Hopper GPUs, it encompasses the TensorRT deep learning compiler, pre and post-processing procedures, optimized kernels, and multi-GPU/multi-node communication. And the best part? No extensive expertise in C++ and NVIDIA CUDA needed.
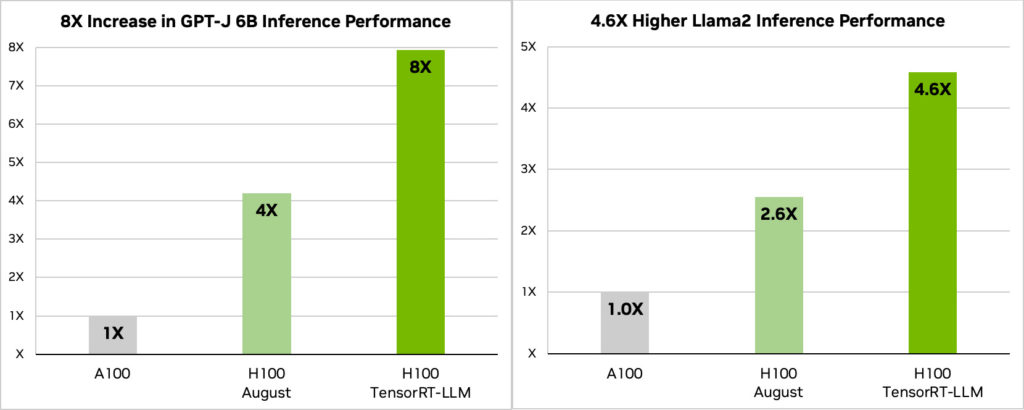
The plotted results provided by NVIDIA shows incredible performance improvement, achieving up to double the inferencing output in GPT-J 6B and approximately 1.77 times the performance boost for Meta’s Llama2.
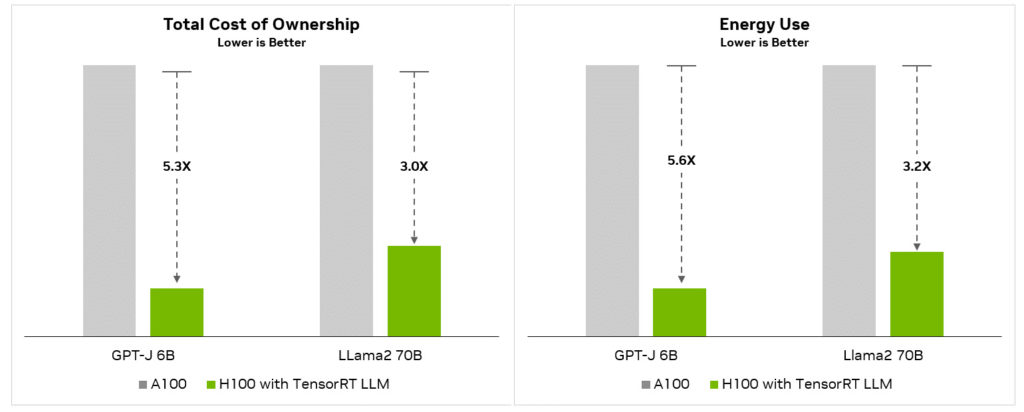 As performance levels increase, particularly on a larger scale, this enhancement will also reduce the Total Cost of Ownership (TCO) and lower energy consumption ratings, providing better financial management and flexibility for data center operators.
As performance levels increase, particularly on a larger scale, this enhancement will also reduce the Total Cost of Ownership (TCO) and lower energy consumption ratings, providing better financial management and flexibility for data center operators.
This means they can scale down for reduced costs or scale up for more hardware off the same baseline costs.
When delving into the technical details of TensorRT-LLM, NVIDIA attributes its success to Tensor Parallelism, which distributes individual weight matrices across devices for efficient inferencing at scale. Additionally, In-flight Batching efficiently processes requests, passing them to the next phase without delay.
The ability to convert model weights into the new FP8 format made possible through the Hopper Transformer Engine, enables rapid quantization with reduced memory consumption. This feature plays a significant role in achieving such impressive performance on the H100.
Availability
Early access to NVIDIA TensorRT-LLM is now accessible and will soon be integrated into the NeMo framework for NVIDIA AI Enterprise. Furthermore, many ready-to-use versions are already optimized, including Meta Llama 2, OpenAI GPT-2 and GPT-3, Falcon, Mosaic MPT, BLOOM, and numerous others, all of which offer a user-friendly Python API.



