

We all know AMD is pretty terrible at the Super PI benchmark and it is not
likely to change. The benchmark is very old and the instruction set it requires
is no longer relevant to real world workloads. It turns out however, that AMD is
worse at Super PI calculations than what the architecture is actually capable
of. The Stilt from Finland figured out how to significantly speed up the
benchmark by going through the BIOS developers guides. The same guides are
available to all the BIOS R&D teams of motherboard vendors, but seemingly no
one figured out this performance issue. It is quite funny and perhaps sad at the
same time that one man is able to beat an entire industry.

Here is the download link to the patch: click
In a video posted by The Stilt earlier, he showed a 4.1GHz A10-6800K
completing SuperPI 17 minutes and 34 seconds. The fastest 5GHz Richland SuperPI
32M is around 18 minutes and 15 seconds. A lot faster! For more information,
check out the thread in the forums(hwbot).
This is his story :
“Exactly two year ago, when I tested a Bulldozer based Zambesi CPU for the first
I was shocked.
The early sample units were even hotter and slower than the
final silicon revision CPUs, which finally were released four months
later.
One of the largest single let-down came from the way back:
SuperPI.
SuperPI mainly uses legacy x87 instructions which have been
almost completely superceded. SuperPI doesn’t show any indication what so ever
about SMP performance as it can only utilize a single thread. On top of that it
has no real world use or purpose as there are newer programs which can calculate
PI almost 100 times faster.
Still, SuperPI can almost be considered as a
industry standard.
Nowdays it is generally a VERY poor indicator of real
world performance, yet it is so addictive for any old school overclocker. It
scales very well along with the CPU/NB/DRAM/IO performance and tweaking it is a
big challenge. An overclocker who hasn’t ever benched SuperPI simply doesn’t
exist.
SuperPI has a special place in my heart simply because it was one
of the first benchmarks I ever ran… almost 14 years ago…
So, why are
all of the 15h (Bulldozer) based CPU/APU/NPUs performing so bad in SuperPI? Some
people say it is because 15h family has 50% less FPs per core than the
preceeding 10h family.
In 15h family a compute unit (two cores) share a FP
when the 10/12h family had a dedicated FP for each of the cores. If this would
be the only reason, the issue would be solved when the “slave” core of the CU is
disabled, leaving a “private” FP for the “master” (BSC) core. However this is
not the case and it even shouldn’t be as SuperPI is single threaded,
remember?
The caches on 15h family have higher latency than 10h family
for example, and SuperPI happens to love large & low latency caches.
15h
family was initially designed for high frequencies. Just like the F1 engines,
they produce no power at low revs. And unfortunately it currently doesn’t seem
to be possible to build an engine capable reving high enough. We might discuss
more about the caches in “Episode 3″… If possible.
Agner Fog
from Copenhagen University College of Engineering has made an excellent document about the instruction latencies of the
modern CPUs.
Values for 10h family start from page 26, while 15h family
values are located at page 36.
Anyway…
Few days when I was doing
some low level testing for other purposes, I found something that didn’t make
any sense to me.
Now I roughly know what it is and what it does, but still
some questions remain: Why does this “feature” exist in the first place and why
it is activated on all 15h family parts. I would normally assume it is a
workaround for some errata, however no bulletin exists for this one either. Also
this feature does not exist in any documentation, or it does but only AMD has
access to the required level. I find it hard to believe that it would be a
design issue as the affected instructions work fine (but slowly) and it existed
since early Zambesi revisions and, currently is still present in Richland and
probably beyond (within family 15h)…
I’d say it is either a errata fix
or a errata fix gone wrong. If it is a programming mistake which has gone
un-noticed during the last two years … That would make me just
sad.
Parts affected: AMD Barracuda (Zambesi, Vishera), AMD Comal
(Trinity, Richland), AMD Virgo (Trinity, Richland)
Effect: A
massive performance hit in application heavily utilizing x87
instructions.
Negative effects: TBD, none found yet. The
performance in non x87 applications remains the same or improves very slightly.
No instability, increased power consumption, reduced overclockability or
anything else abnormal has been observed. However the final conclusion requires
far more extended testing than I am able to do myself.
After the fix has
been applied SuperPI shows 18-30% improvement in performance. Bigger the
calculation, bigger the improvement. Since this kind of fix is quite unheard of,
I knew that I would be crucified if I would make such claims without any
providing evidence.
I generally hate to do videos however this time it
was mandatory. I apologize the quality, 1080p is available but the quality is
quite grainy due poor lightning. It was a cloudy day in Helsinki
today.
The video shows few important things:
- In the video the fix is called as “The Plow of Bulldozer”
- SuperPI 1.5 XS Mod validated by online MD5 checksum
- CPU-Z 1.64.3 x32 validated by online MD5 checksum (can be found from
Stasio’s CPU-Z thread) - The clocks are being shown during the calculation (look for the affinity and
CPU-Z core selection) - An external clock reference is provided (to prove there is no tampering with
the timers, i.e. “Lab Burst” by MSI) - The air cooled setup is shown and so are the CPU temperatures (HWMonitor)
For the 32M SuperPI run (time) you might want to look a reference from HWBot
Piledriver 5G challenge thread.
http://hwbot.org/submission/2386335_…n_14sec_718ms/
39
seconds better time with stock CPU clocks (4.1GHz, NB 2500, MEMCLK DDR-2400)
than on 5GHz Trinity with 2777MHz NB and DDR-2666 memory clocks.
Since I
‘happened’ to have some LN2 in my disposal, I decided to do some high clock
SuperPI runs on Richland.
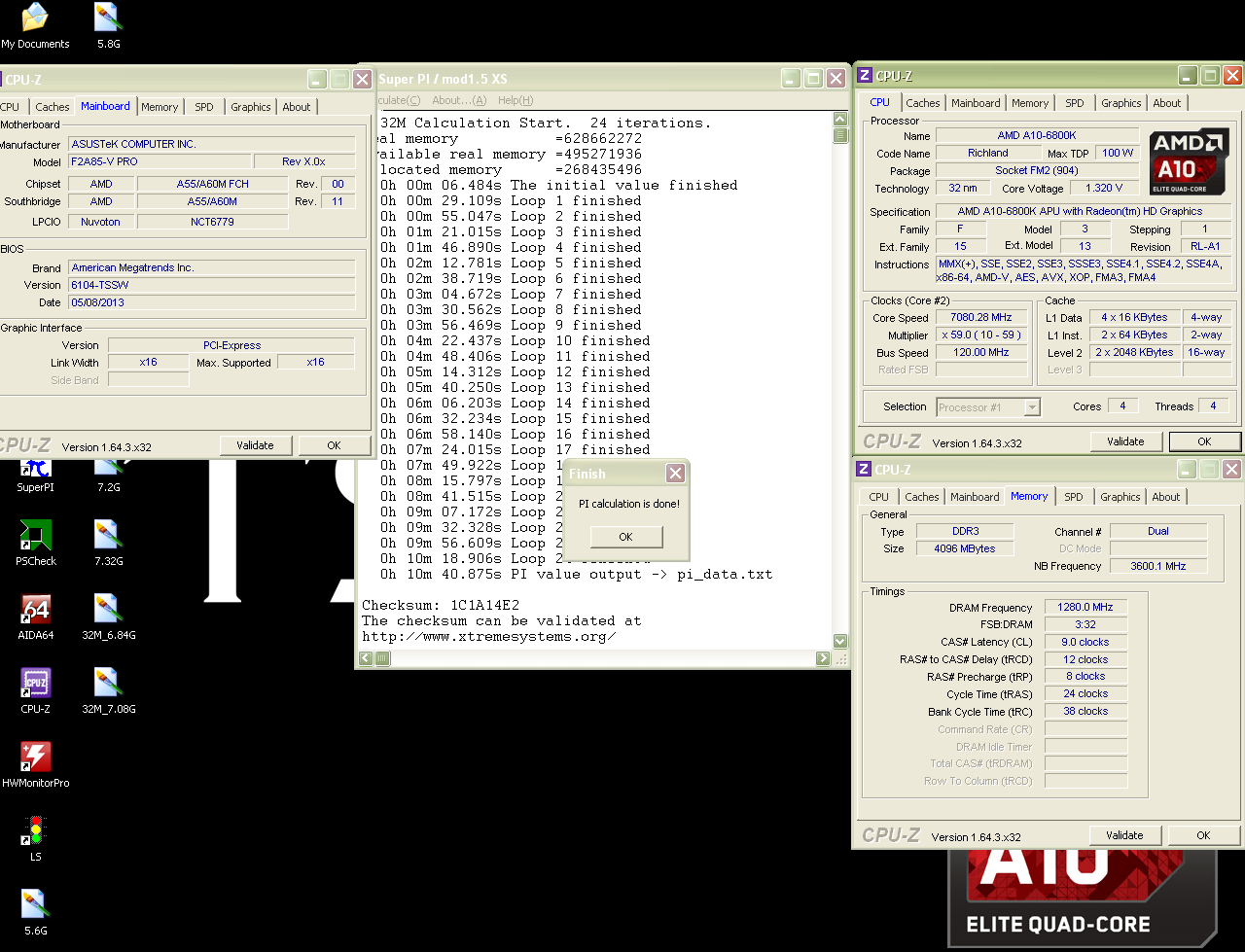

AMD 32nm SuperPI 32M record taken easily. Tomorrow when I throw in a Vishera,
the reign of 10h should be finally over 
All of the runs are either
completely or partially on video.
Will upload them once I have time to edit
them. I’ve been filming around 28GB worth of video during the last 48h hours.
For the LATEST tech updates,
FOLLOW us on our Twitter
LIKE us on our FaceBook
SUBSCRIBE to us on our YouTube Channel!



