


In an exciting leap forward for the AI landscape, OpenAI has collaborated with NVIDIA to release its groundbreaking open-source GPT models, optimized for NVIDIA GPUs. With the release of the gpt-oss-20b and gpt-oss-120b models, developers and AI enthusiasts now have access to cutting-edge AI technology, with powerful inference capabilities directly on local NVIDIA RTX PCs.
These models bring intelligence and reasoning to local computing, opening new possibilities for AI-driven applications like web search, in-depth research, coding assistance, and much more.
The Power of Open-Source GPT Models
OpenAI’s new gpt-oss models are designed with flexibility and scalability in mind, making them perfect for AI developers. Unlike traditional closed models, the gpt-oss-20b and gpt-oss-120b models are open-weight reasoning models that support long context lengths of up to 131,072 tokens, one of the longest available for local inference.
This allows the models to process complex queries and reason through extended conversations or detailed tasks. These models can be easily integrated into a wide range of applications, providing developers with the tools they need to build intelligent, agentic AI systems.
Optimized for NVIDIA RTX GPUs: Speed and Efficiency
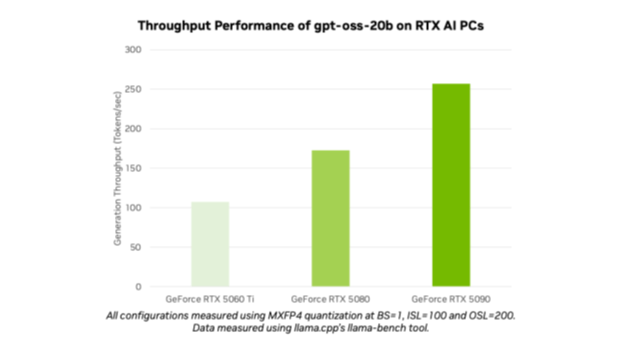
What sets these models apart is their optimization for NVIDIA’s cutting-edge RTX GPUs. NVIDIA’s GeForce RTX 5090 GPU, for instance, can run the models at speeds of up to 256 tokens per second, making them some of the fastest open-source models available for local execution.
This level of optimization delivers smart and fast inference, from the cloud directly to the PC, ensuring high performance with minimal resource usage. Additionally, NVIDIA’s MXFP4 precision type significantly boosts model quality, enabling quicker and more efficient processing while reducing the need for excessive resources compared to traditional precision types.
Simplified Integration with Ollama
For AI enthusiasts and developers eager to experience these powerful models, NVIDIA has introduced the Ollama app. Ollama is designed to be a user-friendly platform that simplifies the testing and deployment of OpenAI’s models on RTX AI PCs. With Ollama, users can easily integrate the models into their workflows, offering out-of-the-box support for OpenAI’s open-weight models without additional configuration.

The app features a simple interface that allows users to select and chat with the models directly, making it an ideal solution for anyone wanting to explore the full capabilities of local AI.
Moreover, Ollama is highly customizable, offering features like PDF and text file support within chats, multimodal capabilities for image-based prompts, and adjustable context lengths for larger documents or in-depth conversations. Whether you’re a casual user or a developer looking to experiment with new applications, Ollama simplifies the process and delivers a powerful AI experience.
Other Options for Using OpenAI’s Models on RTX GPUs
For those who want to explore additional avenues for integrating OpenAI’s models on NVIDIA RTX GPUs, there are multiple options available. Developers can experiment with frameworks like llama.cpp and the GGML tensor library, optimized for RTX GPUs.
NVIDIA continues to collaborate with the open-source community to enhance the performance of these models, with recent contributions aimed at reducing CPU overhead and implementing CUDA Graphs to streamline the process.
Additionally, the Microsoft AI Foundry Local, currently in public preview, offers a seamless integration of OpenAI’s models into workflows. Foundry Local allows developers to invoke models via command line, SDK, or APIs, with the power of CUDA and NVIDIA TensorRT optimization. The integration makes it easy for Windows developers to access and work with OpenAI’s models on their RTX-powered PCs.
Why This Matters for AI
The release of OpenAI’s gpt-oss models optimized for NVIDIA RTX GPUs marks a significant milestone in AI development. By opening up the ability to run powerful reasoning models locally, OpenAI and NVIDIA are setting the stage for the next wave of AI-driven applications.
Developers and enthusiasts can now build more intelligent systems capable of handling complex queries and reasoning tasks, all from the comfort of their own PC.
As these models continue to evolve, the possibilities for AI innovation are endless. Whether you’re building AI applications for business, research, or personal use, the combination of OpenAI’s open-source models and NVIDIA’s RTX GPUs offers an unmatched platform for developing next-generation AI systems.
The Future of AI with OpenAI and NVIDIA RTX
The launch of OpenAI’s open-weight models, optimized for NVIDIA GeForce RTX and RTX PRO GPUs, is a game-changer for the AI community. By making these advanced reasoning models available locally, NVIDIA and OpenAI are empowering developers to create smarter, more efficient AI applications without relying on cloud computing.
The ease of integration, combined with the raw power of NVIDIA’s GPUs, opens up exciting new opportunities for AI-driven solutions. Whether you are an AI enthusiast, developer, or business looking to leverage advanced AI technology, this collaboration is a big step forward in making cutting-edge AI more accessible than ever.



