


NVIDIA has raised the bar in AI inference performance with the debut of its Blackwell Ultra architecture in the latest MLPerf Inference v5.1 benchmark round, delivering record-breaking results across newly added workloads.
 The updated benchmark suite introduced several new tests, including DeepSeek-R1, a 671-billion parameter mixture-of-experts reasoning model, the Llama 3.1 series in both 405B and 8B configurations, and Whisper, the speech recognition model that recently surged in popularity on HuggingFace. NVIDIA achieved top performance across all of these scenarios while maintaining its lead in per-GPU results on established benchmarks.
The updated benchmark suite introduced several new tests, including DeepSeek-R1, a 671-billion parameter mixture-of-experts reasoning model, the Llama 3.1 series in both 405B and 8B configurations, and Whisper, the speech recognition model that recently surged in popularity on HuggingFace. NVIDIA achieved top performance across all of these scenarios while maintaining its lead in per-GPU results on established benchmarks.
The company’s GB300 NVL72 system, powered by Blackwell Ultra, delivered up to 45% higher per-GPU performance than the previous-generation GB200 NVL72, and nearly 5x higher throughput than Hopper-based systems. This translated into significant improvements in AI factory efficiency and lower cost per token. Key advancements included the adoption of NVFP4 quantization for DeepSeek-R1, FP8 precision for KV-cache optimization, and redesigned parallelism techniques that balance workloads across GPUs to minimize latency.
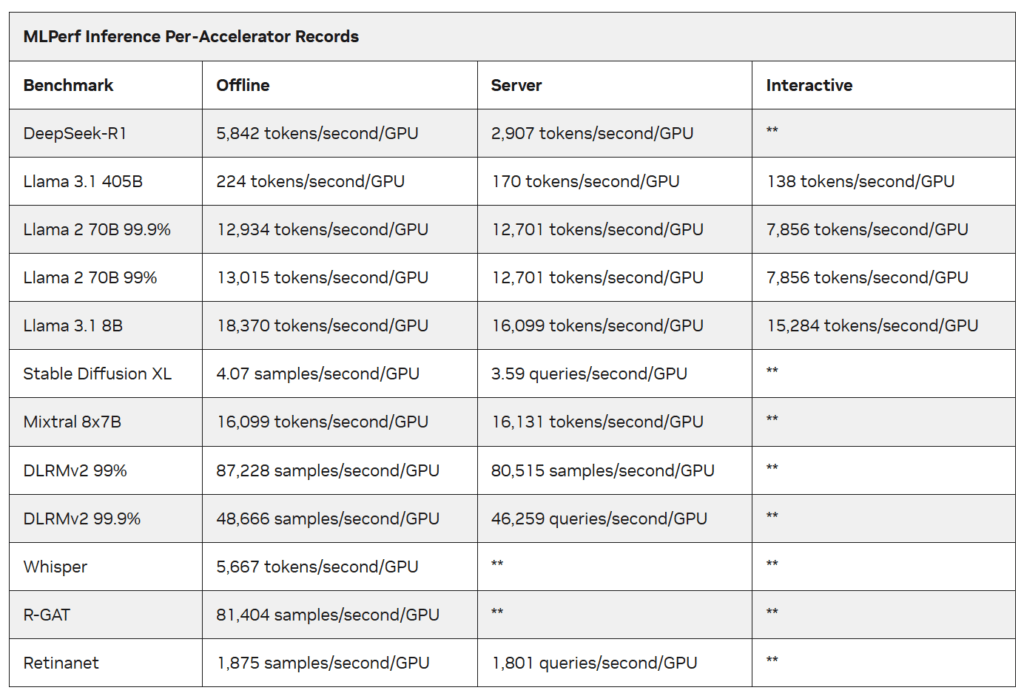 On the newly added Llama 3.1 405B interactive benchmark, NVIDIA also employed disaggregated serving alongside NVLink-based all-to-all communication, enabling nearly 1.5x better throughput per GPU compared to traditional aggregated serving. Together, these innovations allowed the Blackwell Ultra platform to meet stricter latency and token-per-user requirements while sustaining high throughput.
On the newly added Llama 3.1 405B interactive benchmark, NVIDIA also employed disaggregated serving alongside NVLink-based all-to-all communication, enabling nearly 1.5x better throughput per GPU compared to traditional aggregated serving. Together, these innovations allowed the Blackwell Ultra platform to meet stricter latency and token-per-user requirements while sustaining high throughput.
With enhancements such as 1.5x higher NVFP4 compute, 2x attention-layer compute, and expanded HBM3e capacity, Blackwell Ultra establishes a new standard for reasoning performance in AI inference. Coupled with NVIDIA’s inference stack, including TensorRT-LLM and CUDA Graphs, the platform is designed to support the growing computational needs of next-generation large language models.



